You can use a different XPath than the one automatically calculated by Real-Time Designer. Typically, you only need to change this value when there is no stable ID or Name self properties and the location is dynamic. In this case, you should select another element on the page whose relationship is stable.
For example, the windows below show the Google Search button when relating to an HTML page and when relating to a text box, respectively. The XPath value changes accordingly to reflect the new path to the element:
Figure 6-1: XPath when the Google Search button relates to an HTML page
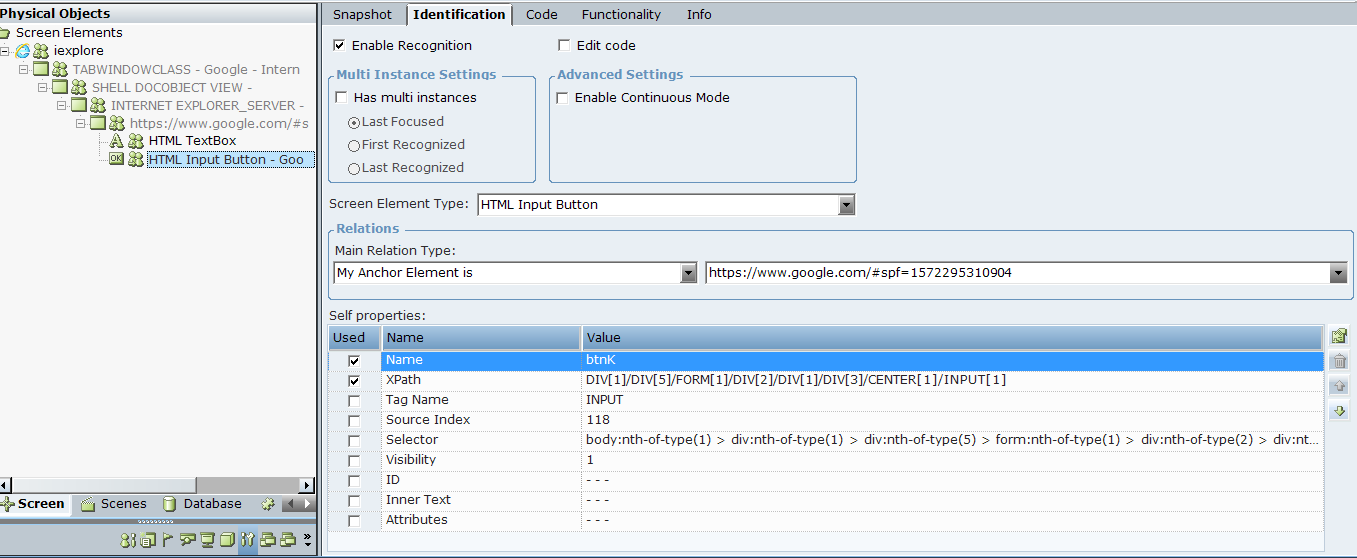
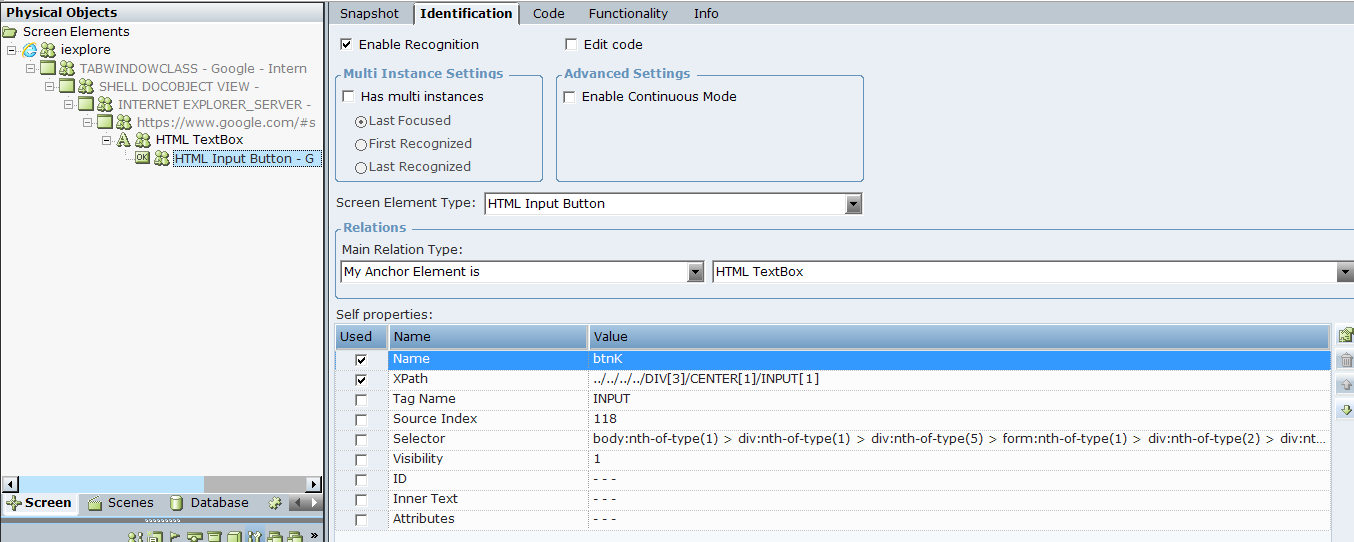
Figure 6-2: XPath when the Google Search button relates to an HTML TextBox (by changing anchor element in the Main Relation Type)
For XPath functionality, the Web Connector can locate HTML elements based on the XPath relative to its sibling elements. This is achieved by using the following prefix options in the XPath self property of the captured HTML element: + or -.
For example, let's say that you have a web page with multiple tables in the same HTML document object model (DOM) level, and you need to identify a specific table based on the identification of one of its sibling tables.
The example is taken from an older release of Real-Time solutions. The idea is to demonstrate how to use the XPath self property in practice. From version 7.2, the Additional Relation Type fields were deprecated.
To use the XPath self property:
-
Capture a cell in the second table.
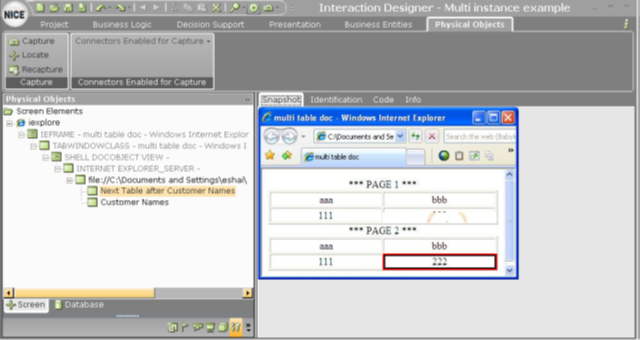
This action generates the following identification parameters.
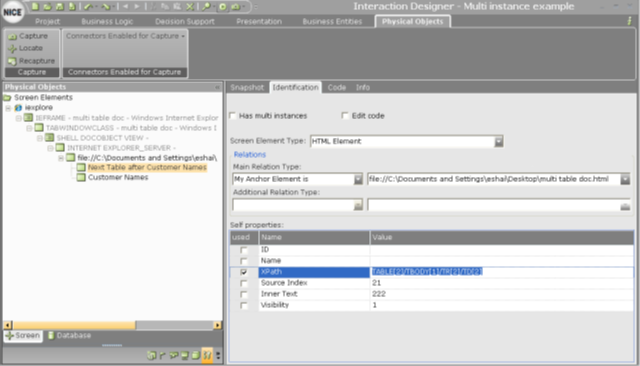
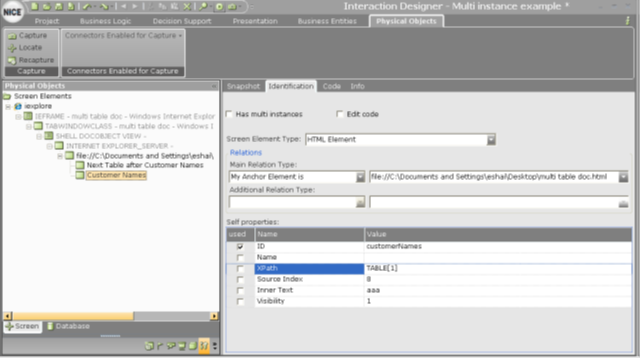
Because the captured table named Next Table after Customer Names has no value in the ID self property, and assuming that the number of tables in the page is dynamic, you cannot rely on the TABLE[x] prefix in the XPath self property to uniquely identify the captured cell.
Now, let's assume that the previous sibling table can be uniquely identified based on its ID self property, which has the value customerNames, as shown below.
-
Anchor Next Table after Customer Names to the Customer Names table.
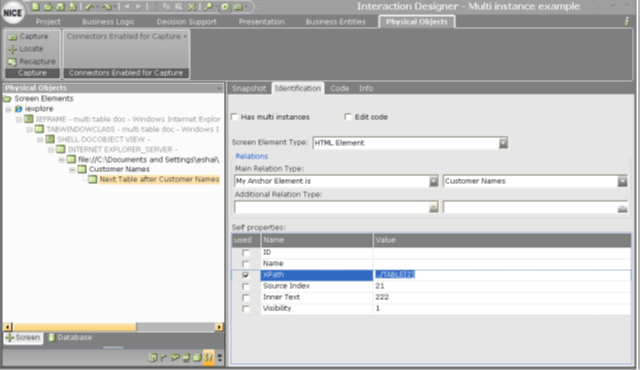
The XPath self property of Next Table After Customer Names is automatically set to express the HTML DOM position relative to the anchor table.
However, you cannot guarantee that these are the first two tables in their containing HTML document, as the HTML document may change dynamically at runtime, adding more tables that precede the Customer Names table.
In such a scenario, the solution is to change the XPath self property of Next Table after Customer Names by adding the + (plus) prefix and setting the relative position of Next Table after Customer Names to Customer Names, which means that +TABLE[1] is the next table after the anchor, as shown below.
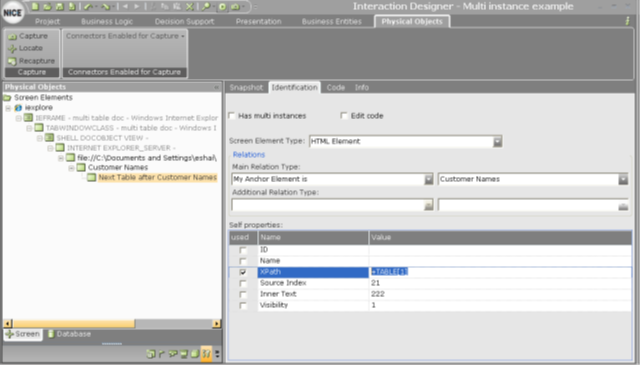
During a real-time identification process, when either the + or - prefixes are encountered, the identification algorithm searches in the element's next (or previous) sibling branches, instead of in the element's children branches.
Modifying the Default XPath Predicates
Configure or modify the default XPath Predicates to identify the similar elements with the predicates defined.
To modify any predicates, review the supported values given below:
Predicates
Each XPath node, separated by /, may be replaced with the predicate (logical function).
-
*[...] for any node
Example:
doc[0]/div[2]/*[2]/*[0]gets nodes with any node name. -
node[*] for any node index
Example:
doc[0]/div[2]/a[*]/div[*]gets nodes with any node index. -
[Num] on node number (index) such as [1]
Example:
doc[0]/div[2]/a[2]/div[0] -
[last()] and [last()-Num] such as [last()-1]
Example:
-
doc[*]/div[last()]/a[2]/div[0]gets the latest node. -
doc[*]/div[last()-1]/a[2]/div[0]gets a node before the latest node.
-
-
[position() < Num], [position() = Num], and [position() > Num]. Supported operators are < or = or >.
Example:
-
doc[*]/div[position()<3]/a[2]/div[0]gets nodes with index 1 and 2 (less than 3). -
doc[*]/div[position()>3]/a[2]/div[0]gets nodes with more than 3. -
doc[*]/div[position()=3]/a[2]/div[0]gets nodes with index 3.
-
-
[position() > Num][2] second node of those returned by first predicate.
-
The predicates, being a logical function, can also be represented as:
-
Unary negation operator NOT and right operand (right predicate).
-
Two operands (left and right predicates) and a binary operator AND/OR between them.
-
A combination of the above predicates and operators. Parentheses and spaces can be used to indicate operator precedence and for readability.
Examples:
-
div[NOT last()]gets all the nodes instead of latest one. -
div[last() OR (position()=1)]gets the latest node or the first node. -
div[(NOT last()) AND (@color OR @weight)]gets all nodes except the latest one that has attribute as color or weight.
Supported Attributes on the nodes
-
[@AttName] indicates one or more nodes that have given attribute.
Example:
[@id]will return nodes with id. -
[@AttName='value'] indicates one or more nodes that have the attribute with value.
Example:
[@class='myclass'] -
[@AttName=contains('value')] indicates one or more nodes where the attribute value contains substring. Wildcards are not supported.
-
[@AttName=starts-with ('value')] indicates one or more nodes where the attribute value starts with the given value.
-
[@AttName=ends-with ('value')] indicates one or more nodes where the attribute value ends with the given value.
-
{kind=link}